Build and deploy a Langchain app with a vector database
Since multiple people asked for a step-by-step of my demo at Cloud Next, here’s a quick walkthrough. Let me know if you have any questions! (send me a message on LinkedIn).
Overview
In this blog post, you’ll learn how to deploy a LangChain app that uses Gemini to let you ask questions over the Cloud Run release notes.
Here’s an example of how the app works: If you ask the question “Can I mount a Cloud Storage bucket as a volume in Cloud Run?”, the app responds with “Yes, since January 19, 2024”, or something similar.
To return grounded responses, the app first retrieves Cloud Run release notes that are similar to the question, then prompts Gemini with both the question and the release notes. (This is a pattern commonly referred to as RAG.) Here’s a diagram showing the architecture of the app:
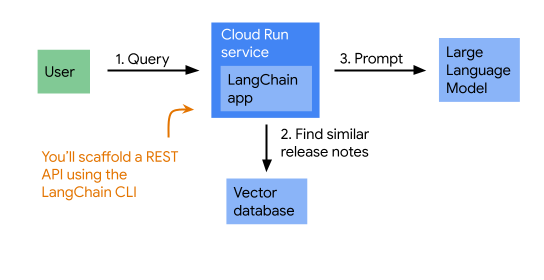
Setup and requirements
First, let’s make sure your development environment is set up correctly.
- You’ll need a Google Cloud project to deploy the resources you’ll need for the app.
- To deploy the app, you need to have gcloud installed on your local machine, authenticated, and configured to use the project.
gcloud auth logingcloud config set project
- If you want to run the application on your local machine, which I recommend, you need to make sure your application default credentials are set up correctly, including setting the quota project.
gcloud auth application-default logingcloud auth application-default set-quota-project
- You also need to have installed the following software:
- Python (version 3.11 or higher is required)
- The LangChain CLI
- poetry for dependency management
- pipx to install and run the LangChain CLI and poetry in isolated virtual environments
Cloud Workstations
Instead of your local machine, you can also use Cloud Workstations (that’s what I did) on Google Cloud. Note that as of April 2024 they both run a Python version lower than 3.11, so you would need to upgrade Python before getting started. I wrote a blog earlier that should help you get you started with installing the tools required for this walkthrough.
Enable the Cloud APIs
First, run the following command to ensure you’ve configured the correct Google Cloud project to use:
gcloud config list project
If the correct project is not showing, you can set it with this command:
gcloud config set project <PROJECT_ID>
Now enable the following APIs:
gcloud services enable \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com \
secretmanager.googleapis.com
Choose a region
Google Cloud is available in many locations globally, and you need to choose one to deploy the resources you’ll use for this lab. Set the region as an environment variable in your shell (later commands use this variable):
export REGION=us-central1
Create the vector database instance
A key part of this app is retrieving release notes that are relevant to the user question. To make that more concrete, if you’re asking a question about Cloud Storage, you want the following release note to be added to the prompt:
January 19, 2024: You can now mount a Cloud Storage bucket as a storage volume for services, and also for Cloud Run jobs.
You can use text embeddings and a vector database to find semantically similar release notes.
I’ll show you how to use PostgreSQL on Cloud SQL as a vector database. Creating a new Cloud SQL instance takes some time, so let’s do that now.
gcloud sql instances create sql-instance \
--database-version POSTGRES_14 \
--tier db-f1-micro \
--region $REGION
You can let this command run and continue with the next steps. At some point you’ll need to create a database and add a user, but let’s not waste time watching the spinner now.
PostgreSQL is a relational database server, and every new instance of Cloud SQL has the extension pgvector installed by default, which means you can also use it as a vector database.
Scaffold the LangChain app
To continue, you’ll need to have the LangChain CLI installed, and poetry to manage dependencies. Here’s how to install those using pipx:
pipx install langchain-cli poetry
Scaffold the LangChain app with the following command. When asked, name the folder run-rag and skip installing packages by pressing enter:
langchain app new
Change into the run-rag directory and install dependencies
poetry install
You’ve just created a LangServe app. LangServe wraps FastAPI around a LangChain chain. It comes with a built-in playground that makes it easy to send prompts and inspect the results, including all intermediary steps. I suggest you open the folder run-rag in your editor and explore what’s there.
Create the indexing job
Before you start putting together the web app, let’s make sure the Cloud Run release notes are indexed in the Cloud SQL database. In this section, you’ll create an indexing job that does the following:
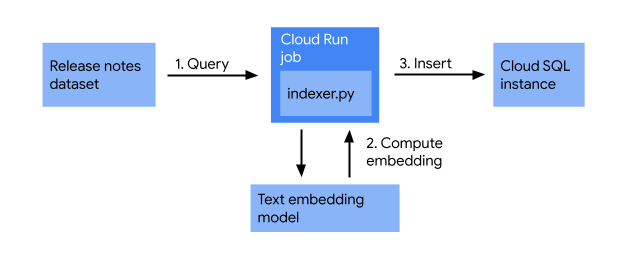
The indexing job takes release notes, converts them into vectors using a text embedding model, and stores them in a vector database. This enables efficient searching for similar release notes based on their semantic meaning.
In the run-rag/app folder, create a file indexer.py with the following content:
import os
from google.cloud.sql.connector import Connector
import pg8000
from langchain_community.vectorstores.pgvector import PGVector
from langchain_google_vertexai import VertexAIEmbeddings
from google.cloud import bigquery
# Retrieve all Cloud Run release notes from BigQuery
client = bigquery.Client()
query = """
SELECT
CONCAT(FORMAT_DATE("%B %d, %Y", published_at), ": ", description) AS release_note
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE product_name= "Cloud Run"
ORDER BY published_at DESC
"""
rows = client.query(query)
print(f"Number of release notes retrieved: {rows.result().total_rows}")
# Set up a PGVector instance
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
store = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
),
pre_delete_collection=True
)
# Save all release notes into the Cloud SQL database
texts = list(row["release_note"] for row in rows)
ids = store.add_texts(texts)
print(f"Done saving: {len(ids)} release notes")
Add the required dependencies:
poetry add \
cloud-sql-python-connector["pg8000"] \
langchain-google-vertexai \
langchain-community \
pgvector
Create the database and a user
Create a database release-notes on the Cloud SQL instance sql-instance:
gcloud sql databases create release-notes --instance sql-instance
Create a database user called app:
gcloud sql users create app --instance sql-instance --password "myprecious"
Note that I’m using an easy to guess password here, to make the instructions easier to follow. Outside of the lab, it’s strongly recommended to do the following instead:
- Generate a random password.
- Store the password in Secret Manager.
- Expose the secret as an environment variable (or mounted as a file) to your application.
Deploy and run the indexing job
Now deploy and run the job:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)")
gcloud run jobs deploy indexer \
--source . \
--command python \
--args app/indexer.py \
--set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \
--set-env-vars=DB_USER=app \
--set-env-vars=DB_NAME=release-notes \
--set-env-vars=DB_PASS=myprecious \
--region=$REGION \
--execute-now
That’s a long command, let’s look at what is happening:
The first command retrieves the connection name (a unique ID formatted as project:region:instance) and sets it as the environment variable DB_INSTANCE_NAME.
The second command deploys the Cloud Run job. Here’s what the flags do:
--source .: Specifies that the source code for the job is in the current working directory (the directory where you’re running the command).--command python: Sets the command to execute inside the container. In this case, it’s to run Python.--args app/indexer.py: Provides the arguments to the python command. This tells it to run the script indexer.py in the app directory.--set-env-vars: Sets environment variables that the Python script can access during execution.--region=$REGION: Specifies the region where the job should be deployed.--execute-now: Tells Cloud Run to start the job immediately after it’s deployed.
To verify that the job successfully completed, you can do the following:
- Read the logs of the job execution through the web console. It should report “Done saving: xxx release notes” (where xxx is the number of release notes saved).
- You can also navigate to the Cloud SQL instance in the web console, and use the Cloud SQL Studio to query the number of records in the
langchain_pg_embeddingtable.
Write the web application
Open the file app/server.py in your editor. You’ll find a line that says the following:
# Edit this to add the chain you want to add
Replace that comment with the following snippet:
# (1) Initialize VectorStore
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
vectorstore = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
)
)
# (2) Build retriever
def concatenate_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
notes_retriever = vectorstore.as_retriever() | concatenate_docs
# (3) Create prompt template
prompt_template = PromptTemplate.from_template(
"""You are a Cloud Run expert answering questions.
Use the retrieved release notes to answer questions
Give a concise answer, and if you are unsure of the answer, just say so.
Release notes: {notes}
Here is your question: {query}
Your answer: """)
# (4) Initialize LLM
llm = VertexAI(
model_name="gemini-1.0-pro-001",
temperature=0.2,
max_output_tokens=100,
top_k=40,
top_p=0.95
)
# (5) Chain everything together
chain = (
RunnableParallel({
"notes": notes_retriever,
"query": RunnablePassthrough()
})
| prompt_template
| llm
| StrOutputParser()
)
You also need to add these imports:
import pg8000
import os
from google.cloud.sql.connector import Connector
from langchain_google_vertexai import VertexAI
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores.pgvector import PGVector
Finally, change the line that says “NotImplemented” to:
# add_routes(app, NotImplemented)
add_routes(app, chain)
Deploy the web application to Cloud Run
From the run-rag directory, use the following command to deploy the app to Cloud Run:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)")
gcloud run deploy run-rag \
--source . \
--set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \
--set-env-vars=DB_USER=app \
--set-env-vars=DB_NAME=release-notes \
--set-env-vars=DB_PASS=myprecious \
--region=$REGION \
--allow-unauthenticated
This command does the following:
- Upload the source code to Cloud Build
- Run docker build.
- Push the resulting container image to Artifact Registry.
- Create a Cloud Run service using the container image.
When the command completes, it lists an HTTPS URL on the run.app domain. This is the public URL of your new Cloud Run service
Explore the playground
Open the Cloud Run service URL and navigate to /playground. It brings up a text field. Use it to ask questions over the Cloud Run release notes, like here:
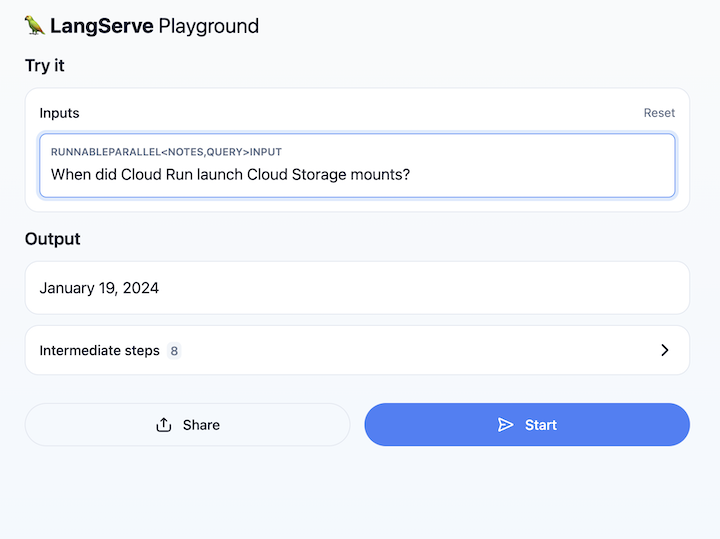
Congratulations
You have successfully built and deployed a LangChain app on Cloud Run. Well done!
Here are the key concepts:
- Using the LangChain framework to build a Retrieval Augmented Generation (RAG) application.
- Using PostgreSQL on Cloud SQL as a vector database with pgvector, which is installed by default on Cloud SQL.
- Run a longer running indexing job as a Cloud Run jobs and a web application as a Cloud Run service.
- Wrap a LangChain chain in a FastAPI application with LangServe, providing a convenient interface to interact with your RAG app.
Clean up
To avoid incurring charges to your Google Cloud Platform account for the resources used in this tutorial:
- In the Cloud Console, go to the Manage resources page.
- In the project list, select your project then click Delete.
- In the dialog, type the project ID and then click Shut down to delete the project.
If you want to keep the project, make sure to delete the following resources:
- Cloud SQL instance
- Cloud Run service
- Cloud Run job
That’s it, let me know what you think!